
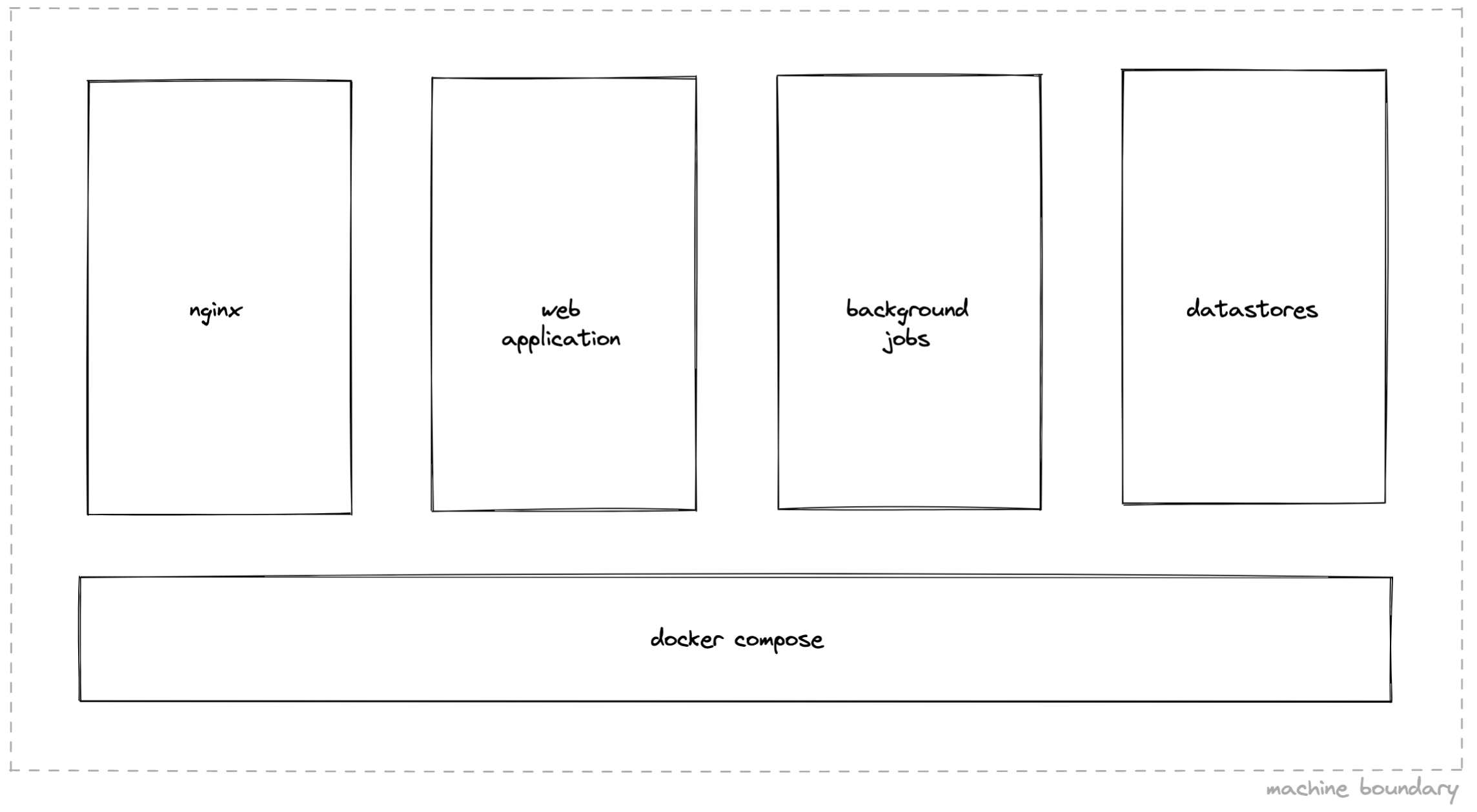
Tines has a familiar architecture:
Our web application handles web requests served by nginx
Background jobs (e.g. those powering Tines Actions) run in a separate process
Data rests in external services like Postgres and Redis
More unusually, we allow customers to self-host Tines on premise, alongside our usual cloud offering. In this configuration, all of the above – the web application, background jobs, and datastores – run on a single machine, in containers orchestrated by docker-compose.
We were faced with an interesting question: how can we safely deploy changes in this configuration without dropping web requests? (Answering this question is key to achieving continuous deployment, which we care deeply about.)
Pare down the problem
First off, we rarely make any changes to the containers running our datastores, so we can eliminate those from our consideration. And we don't need to worry about our background jobs either: those will retry automatically once the deployment finishes, so brief downtime just isn’t an issue.
That leaves our web application. The common advice we heard for achieving what we needed was:
Run an nginx wrapper which reloads nginx on container changes, or
Use docker swarm, or
Use a dedicated application proxy like Traefik
Each of these held promise, but might there be a solution out there that didn't add the risk and future maintenance cost of a new dependency?
Just add bash
We found a surprisingly simple solution to the problem.
First of all, we deleted a line in our docker-compose configuration file, removing our static container_name declaration. With this change, docker-compose can start multiple versions of the container side-by-side (tines-app-1, tines-app-2, …).
Next, we added a bash script, to coordinate deployments. This was what ours looked like:
reload_nginx() {
docker exec nginx /usr/sbin/nginx -s reload
}
zero_downtime_deploy() {
service_name=tines-app
old_container_id=$(docker ps -f name=$service_name -q | tail -n1)
# bring a new container online, running new code
# (nginx continues routing to the old container only)
docker-compose up -d --no-deps --scale $service_name=2 --no-recreate $service_name
# wait for new container to be available
new_container_id=$(docker ps -f name=$service_name -q | head -n1)
new_container_ip=$(docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $new_container_id)
curl --silent --include --retry-connrefused --retry 30 --retry-delay 1 --fail http://$new_container_ip:3000/ || exit 1
# start routing requests to the new container (as well as the old)
reload_nginx
# take the old container offline
docker stop $old_container_id
docker rm $old_container_id
docker-compose up -d --no-deps --scale $service_name=1 --no-recreate $service_name
# stop routing requests to the old container
reload_nginx
}Once this script has run, our web container is guaranteed to be up-to-date, so we take care of the other containers as usual:
docker-compose upCould it be that easy?
The central piece that makes this work is nginx's own reload function. As the nginx docs explain, this is itself zero-downtime:
Old worker processes, receiving a command to shut down, stop accepting new connections and continue to service current requests until all such requests are serviced. After that, the old worker processes exit.
But we were still surprised to see that this worked, as it conflicted with all of the advice we read online.
To be sure, we tested by hammering a test instance during a deployment of a version change, ensuring that all requests resolved successfully. If you look closely in the output, you'll see it go from consistent v1, to a mixture of v1/v2, to consistent v2.

We’ve been using this in production for over 6 months without issue.
‘Plain old engineering’
Generally, we have a strong bias towards simple and boring technical solutions at Tines – we'd rather spend our brain cycles thinking about customer problems and improving our product.
So when making changes to product code, we first ask ourselves: could a plain old Ruby/JavaScript object do the job here instead of that fancy library solution? We've found that a similar attitude works all over the stack: from figuring out how we should write our CSS, to solving infrastructure problems like this one.
If this resonates, we’re hiring.