



The story of how Tines scales starts in the product with, well, a story. Any user of Tines will be familiar with the basic concepts of actions and events. They know that when an action receives an event, it runs in order to, e.g., transform that event data or send it off to an API. They also know that when the action has finished running, it will usually emit an event containing its results – an event that will then be sent onwards, to other actions, causing them to run in turn.

The deceptive simplicity of this model is incredibly valuable for making the product easy to use. To reason about and configure any single action, a Tines user doesn’t have to think about what else might be happening elsewhere in a story at the same moment. They can focus solely on the action in question, the event data it has received and the event data it needs to produce.
This model, where we need to only reason about how any one individual action runs at a time, is also fundamental to how Tines scales. The code and systems responsible for executing a single action don’t need to worry about what any other action executions might be doing at the same time. In any one moment, it doesn’t matter whether one, a thousand or a hundred thousand actions are executing – they all do so in isolation.
In building Tines, we start with a product that’s fundamentally scalable in its design. There’s no theoretical limit to how many actions can run at any given moment, how many pieces of isolated work can execute in parallel. In practice, then, our challenge is to craft a system that avoids unnecessary bottlenecks, so it can chew through as many of these isolated pieces of work as possible, as fast as possible.
Working in parallel
To put this theory into practice, we’ve architected a system that allows us to “fan out” instructions to run actions to a horizontally scalable set of workers, all executing their work in parallel.
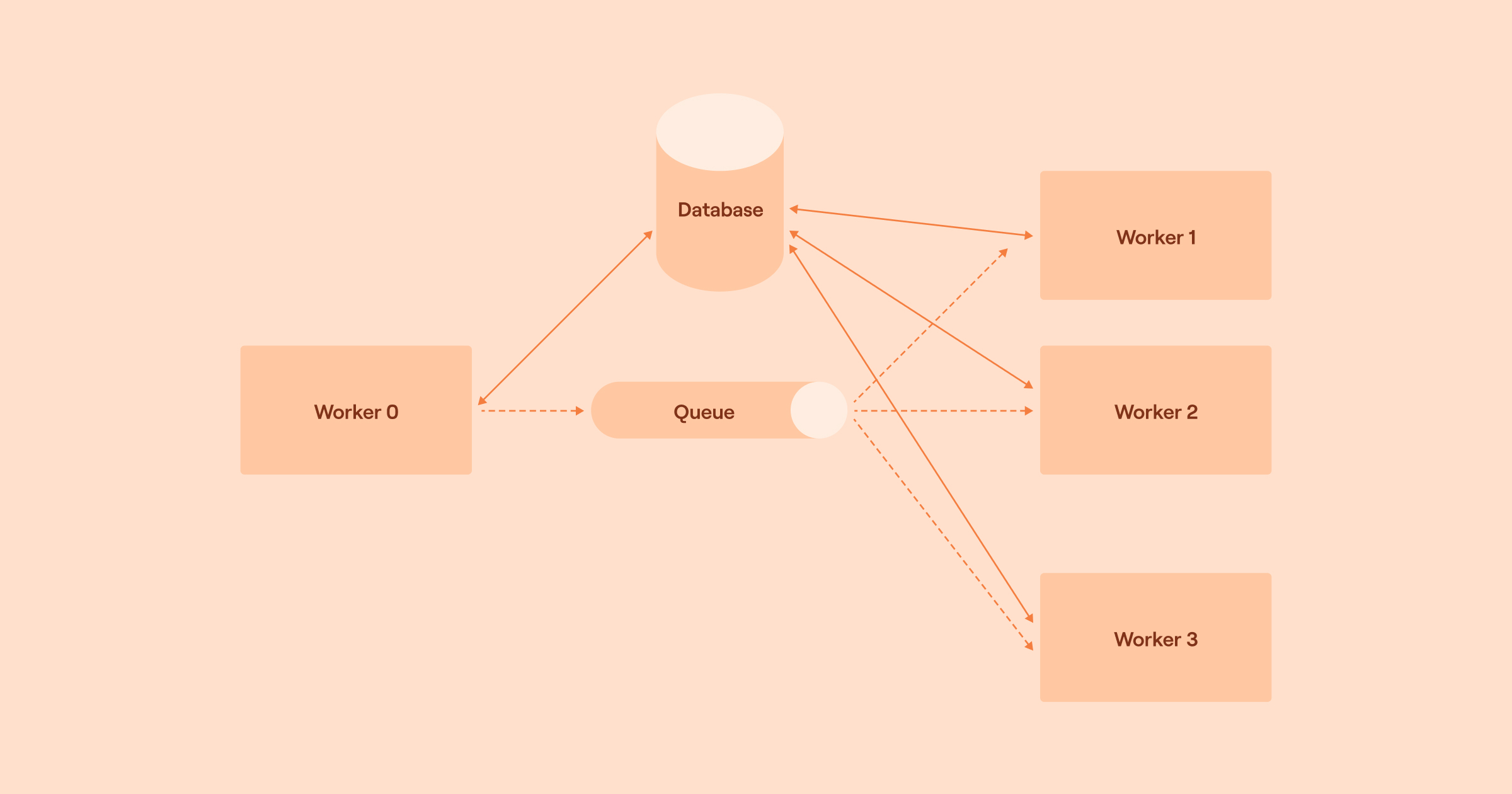
When a worker picks up an instruction to run an action, it:
Loads the details of the action and the event data the action has received from the database.
Interpolates event data into the action configuration and runs the action with that configuration.
Writes the resulting data for the event(s) produced to the database.
Writes an instruction to run an action to the database for each event produced and each downstream action that will need to run as a result.
Uses the message queue to signal available workers with the identifiers of those instructions – each worker that picks up a message starts again at step 1.
These are standard patterns for executing workloads of this type, standard patterns that help us make scaling more straightforward. Generally speaking, the more workers and database capacity in the system, the more work the system can handle. Workers can be dynamically added as demand requires. At peak, across all of our cloud infrastructure, we’ll typically be running around 15,000 such workers.
Avoiding bottlenecks
Day-to-day, the majority of our engineering challenges in scaling our system come in removing and avoiding moments where we start to violate that all important property of our system that individual actions can be run in isolation.
As an example, our product tracks and surfaces the “last run” time for each action. Naively implemented, this would require updating a timestamp every time an action runs. When the same action is running in parallel hundreds or thousands of times for separate events, a naive system would attempt to update the same row of a database thousands of times per second. This contention can create a bottleneck, meaning that more workers won’t necessarily allow the system to process more data.
However, in this case, we know that if two or more workers are attempting to update the last run time at the same moment, to set it to the same value, we only need one of those updates to complete. With this in mind, we can optimize the system: the first worker to come along acquires a lock and proceeds to make the update; the second and subsequent workers, on encountering the lock, happily skip over this operation, safe in the knowledge that the timestamp will be correctly updated by the first worker.
The total number of action runs happening across our cloud infrastructure is growing by about 50% every two months. We’re also adding new features at an astonishing rate: so far in 2023 we’ve announced an average of 12 new features each month. To stay ahead of this growth in both the size of workload and the capabilities of the product, we’re constantly engineering similar solutions, avoiding moments where contention and bottlenecks can arise, to ensure our system continues to scale.
In numbers: a load test
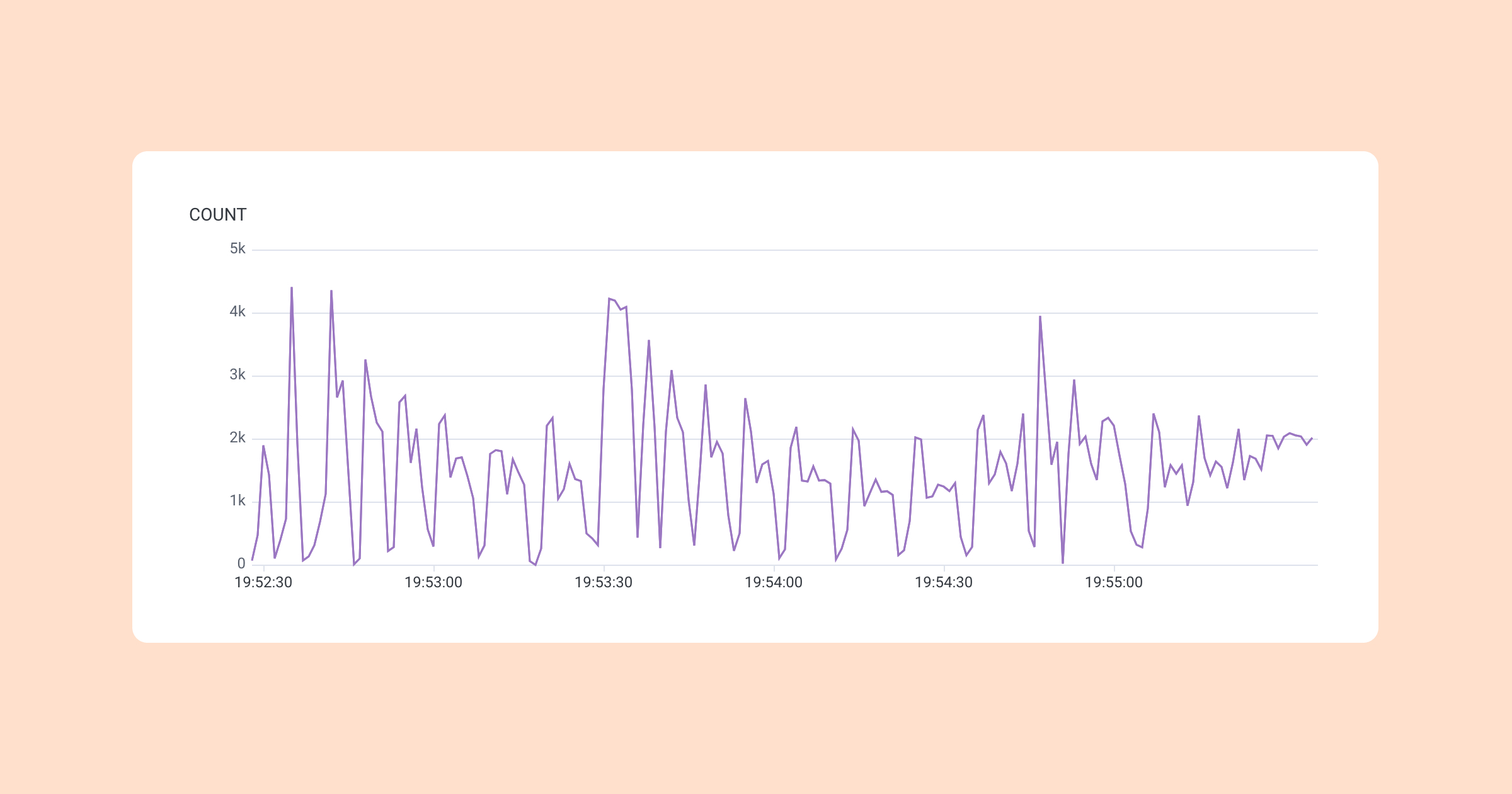
In practice, where does all of this lead us? We recently performed a load test of our system by doing thousands of parallel runs of a single story with many branches. We deployed this experiment on a AWS Aurora R7G.16XLarge Database, supported by 100 ECS Tasks running our workers, for a total of 1,200 worker threads). The results? We were able to achieve a peak performance above 4,000 action runs per second for our story, generating downstream events at a rate of 10,000 events per second. Here’s a snapshot from our observability platform, Honeycomb, showing action runs per second:
Conclusion
Tines scales by design and by default. Our approach to scaling starts with the fundamental workings of our product, and continues through to the use of industry-standard tools and best practices in our execution. We’re continuously refining and improving our strategies, technical design choices and techniques to keep our system scaling as our feature set and traffic levels grow exponentially.